Essential Machine Learning Algorithms for Prediction
Essential Machine Learning Algorithms For Predictive Modeling
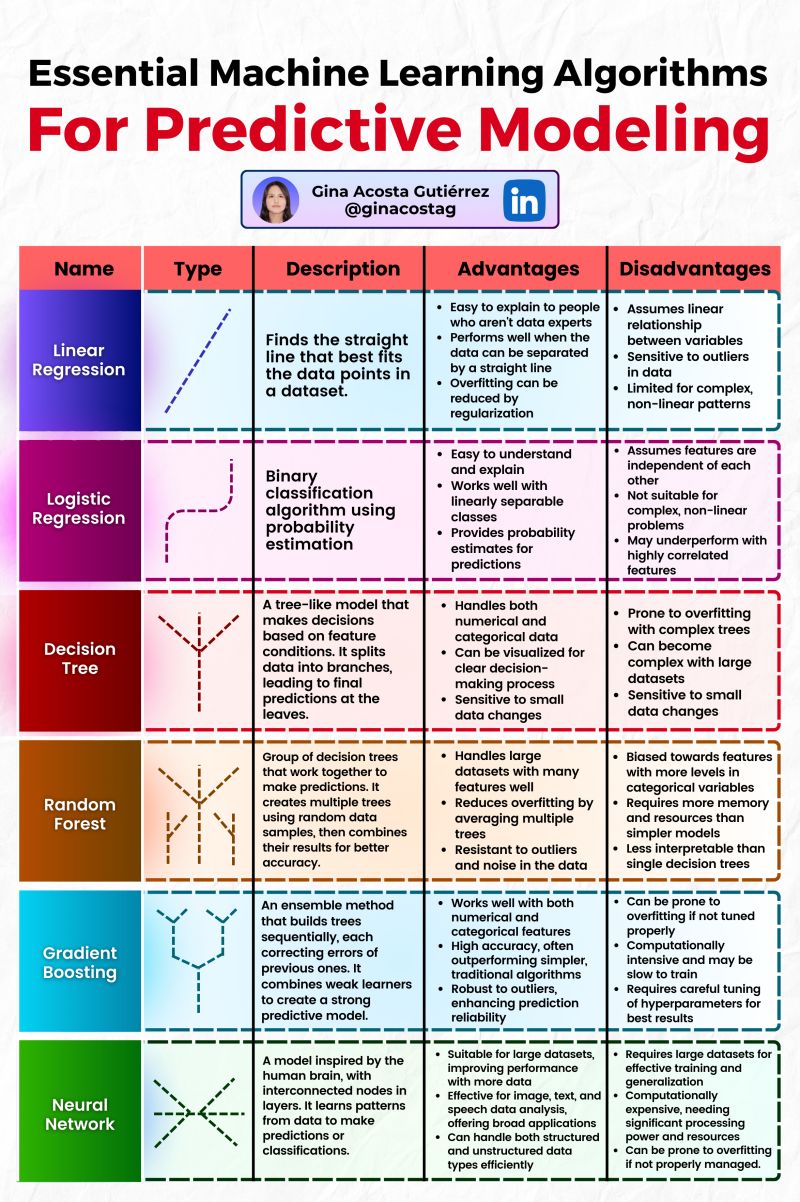
Linear Regression
- Type: Supervised
- Description: Finds the straight line that best fits the data points in a dataset.
- Advantages:
- Easy to Explain: This makes it accessible for non-data experts and is often the first algorithm taught due to its simplicity.
- Performs Well for Linearly Separable Data: Especially effective when the data can be separated by a straight line.
- Reduction of Overfitting by Regularization: Techniques like Ridge and Lasso regression can reduce the risk of overfitting.
- Disadvantages:
- Assumes Linear Relationship: Fails to capture more complex patterns within the data.
- Sensitivity to Outliers: Outliers can heavily influence the results.
- Limited for Complex Data: Not suitable for non-linear patterns.
Logistic Regression
- Type: Supervised
- Description: Binary classification algorithm using probability estimation.
- Advantages:
- Easy to Understand: Like linear regression, it is easy to explain and implement.
- Effective for Linearly Separable Classes: Works well when the classes in the data are linearly separable.
- Probability Estimation: Provides class probability estimates for predictions.
- Disadvantages:
- Feature Independence Assumption: Assumes features are independent of each other, which might not always be the case.
- Limited to Linear Problems: Not suitable for complex, non-linear problems.
- Performance Decrease with Correlated Features: May underperform if the features are correlated.
Decision Tree
- Type: Supervised
- Description: A tree-like model that makes decisions based on feature conditions, splitting data into branches.
- Advantages:
- Handles Various Data Types: Can manage both numerical and categorical data.
- Visual Interpretability: Can be visualized for easier decision-making processes.
- Sensitive to Small Data Changes: Can capture intricate patterns.
- Disadvantages:
- Prone to Overfitting: Especially when the tree is deep.
- Scalability Issues: Performance can degrade with very large datasets.
- High Sensitivity: Sensitive to small changes in data.
Random Forest
- Type: Supervised
- Description: Ensemble of multiple decision trees, combining their predictions for better accuracy.
- Advantages:
- Handles Large Datasets: Efficiently processes large datasets with many features.
- Reduces Overfitting: By averaging multiple trees, it mitigates the risk of overfitting.
- Resilient to Outliers and Noise: Less sensitive to overfitting compared to single decision trees.
- Disadvantages:
- Bias towards Features with Many Levels: Tends to favor categorical variables with numerous levels.
- Resource Intensive: Requires more memory and computational resources.
- Complexity: Less interpretable than individual decision trees.
Gradient Boosting
- Type: Supervised
- Description: Builds an ensemble of trees incrementally, correcting errors of previous ones.
- Advantages:
- Versatile: Effective for both numerical and categorical data.
- High Accuracy: Often outperforms simpler, unoptimized models.
- Robust to Outliers: Built to handle a variety of data anomalies.
- Disadvantages:
- Tuning Required: Hyperparameter tuning is essential for optimal performance.
- Computation Intensive: Can be slow to train, requiring significant processing power.
- Prone to Overfitting: If not sufficiently tuned, it may overfit the data.
Neural Network
- Type: Supervised
- Description: Mimics the human brain, using interconnected nodes in layers to learn patterns.
- Advantages:
- Scalable: Suitable for large datasets, scales well with data size.
- Diverse Applications: Effective for image, text, and speech analysis.
- Adaptable: Can learn broad applications using structured and unstructured data.
- Disadvantages:
- Data Dependencies: Requires large datasets for effective training.
- Computational Resources: Intensive in terms of processing power and time.
- Tuning Complexity: Needs significant tuning for best results.
- Overfitting: Risk of overfitting if not properly managed.
Reference:
elitedatascience.com
Modern Machine Learning Algorithms: Strengths and Weaknesses
www.geeksforgeeks.org
What are the Advantages and Disadvantages of Random Forest?
www.analyticsvidhya.com
Top 10 Machine Learning Algorithms to Use in 2024 - Analytics Vidhya