GPT o1 Model: Major Advancements in AI Reasoning Performance
Evals
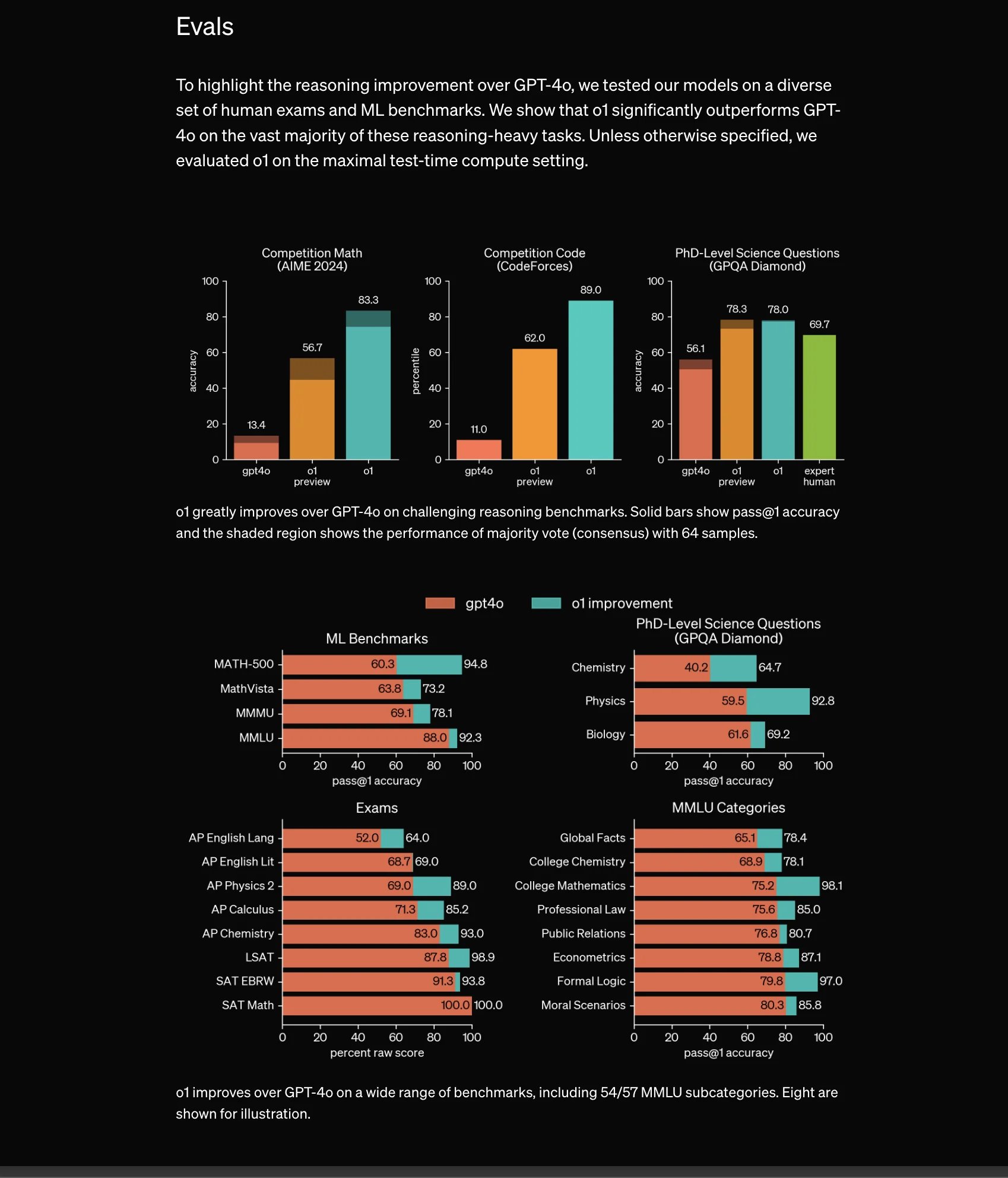
Reasoning Improvements
- Overview: The image evaluates the reasoning improvement of a new model, labelled as "o1," compared to GPT-4o, on various human exams and machine learning benchmarks.
- Thoughts: Demonstrating the capability of AI models on complex reasoning tasks exhibits advancements in artificial intelligence.
Exam Settings
- Maximal Test-Time Compute Setting: o1 was tested under these conditions unless specified otherwise.
- Explanation: This ensures that o1 is evaluated under consistent and optimal settings to reflect its true capabilities.
Key Performance Insights
Competition Math (AIME 2024)
| Metric | GPT-4o | o1 Preview | o1 |
|---|---|---|---|
| Accuracy | 13.4% | 83.3% |
- Thoughts: The significant improvement from 13.4% to 83.3% underscores the enhanced reasoning capabilities of o1.
Competition Code (CodeForces)
| Metric | GPT-4o | o1 Preview | o1 |
|---|---|---|---|
| Percentile | 11.0 | 62.0% |
- Thoughts: Highlighting coding benchmarks can be crucial for evaluating models used in software development.
PhD-Level Science Questions (GPOA Diamond)
| Metric | GPT-4o | o1 Preview | o1 | Expert Human |
|---|---|---|---|---|
| Accuracy | 56.1% | 78.3% | 78.0% | 69.7% |
- Thoughts: Showing comparison with human experts provides a benchmark for human-level reasoning abilities in science.
ML Benchmarks
| Benchmark | GPT-4o | o1 Improvement |
|---|---|---|
| MATH-500 | 60.3 | 94.8 |
| MathVista | 63.8 | 73.2 |
| MMML | 69.1 | 78.1 |
| MMLU | 88.0 | 92.3 |
- Explanation: ML benchmarks are essential to evaluate the AI model’s performance in machine learning tasks.
PhD-Level Science Questions (GPOA Diamond)
| Subject | GPT-4o | o1 Improvement |
|---|---|---|
| Chemistry | 40.2 | 64.7 |
| Physics | 59.5 | 92.8 |
| Biology | 61.6 | 69.2 |
- Explanation: Assessing performance across different fields of science demonstrates the model's breadth of knowledge.
Exams
| Exam | GPT-4o | o1 Improvement |
|---|---|---|
| AP English Lang | 52.0 | 64.0 |
| AP English Lit | 68.7 | 69.0 |
| AP Physics 2 | 65.9 | 89.0 |
| AP Calculus | 71.3 | 85.2 |
| AP Chemistry | 83.0 | 93.0 |
| LSAT | 87.8 | 98.9 |
| SAT EBRW | 91.3 | 93.8 |
| SAT Math | 100.0 | 100.0 |
- Thoughts: Performance on standardized exams shows applicability in educational assessments.
MMLU Categories
| Category | GPT-4o | o1 Improvement |
|---|---|---|
| Global Facts | 65.1 | 78.4 |
| College Chemistry | 68.9 | 78.1 |
| College Mathematics | 75.6 | 98.1 |
| Professional Law | 75.6 | 85.0 |
| Public Relations | 76.8 | 87.1 |
| Econometrics | 79.8 | 97.0 |
| Formal Logic | 85.3 | 92.3 |
| Moral Scenarios | 83.0 | 85.8 |
- Explanation: Varied categories indicate the model’s capability across different fields of knowledge and logic.
Summary
- o1's Superiority: On a majority of benchmarks, o1 significantly outperforms GPT-4o, indicating a noticeable improvement in reasoning tasks.
- Thoughts: This signifies progressive evolution in AI models towards robust and accurate problem-solving abilities.
Reference:
openai.com
Learning to Reason with LLMs | OpenAI
www.cognition.ai
A review of OpenAI o1 and how we evaluate coding agents
venturebeat.com
OpenAI launches new AI model o1 with PhD-level performance