System Design Interview Framework & API Choices Guide
System Design Interview Cheat Sheet
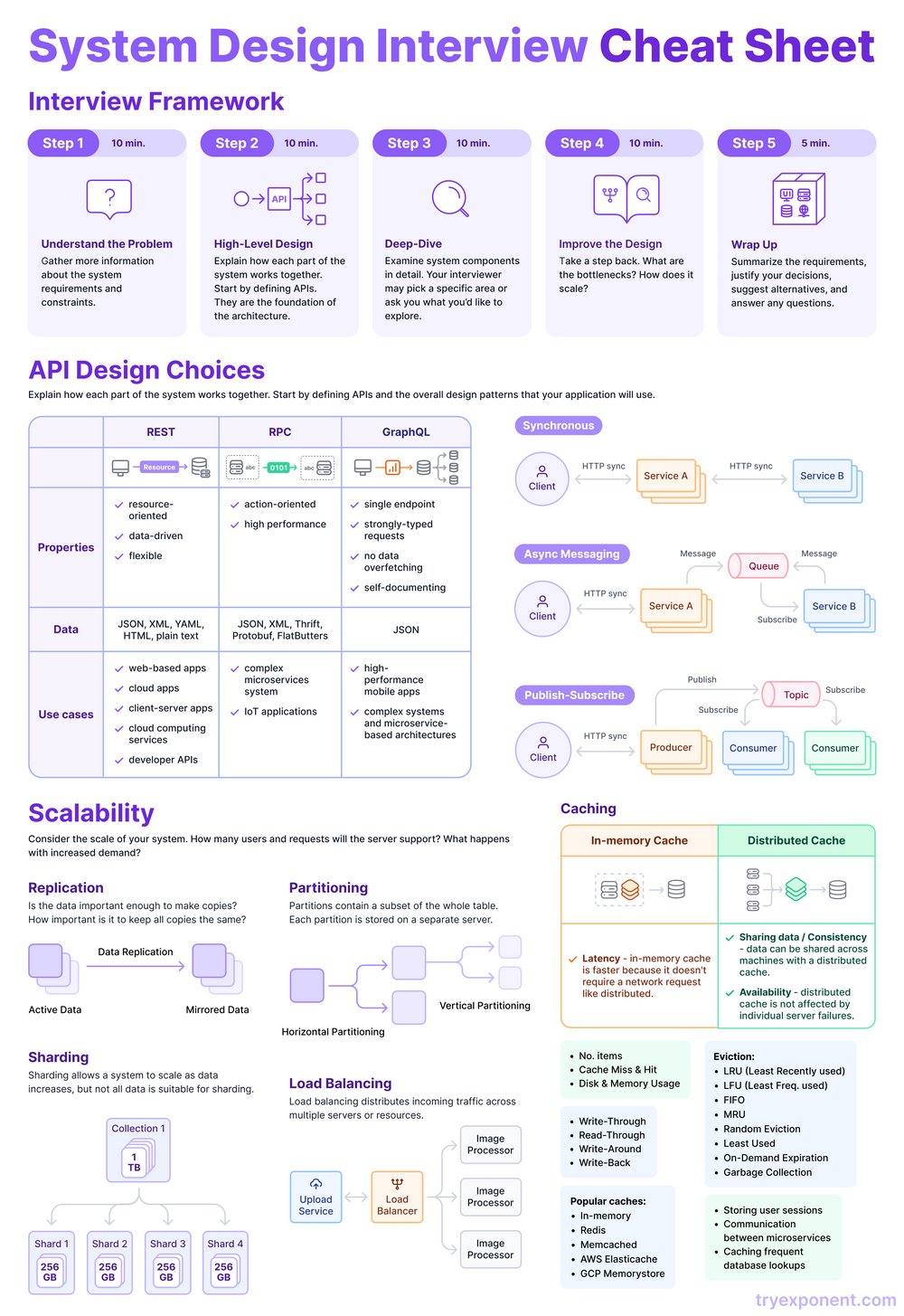
Interview Framework
Step 1: Understand the Problem (10 min)
- Gather more information about the system requirements and constraints.
- Thought: Achieving a clear understanding early on will help in shaping the entire design process.
Step 2: High-Level Design (10 min)
- Explain how each part of the system works together. Start by defining APIs.
- APIs create the foundation of the architecture.
Step 3: Deep-Dive (10 min)
- Examine system components in detail.
- Be prepared to discuss specific areas or request to explore particular components.
Step 4: Improve the Design (10 min)
- Analyze bottlenecks and scalability.
- Identify potential areas for optimization and improvement.
Step 5: Wrap Up (5 min)
- Summarize the requirements, justify decisions, suggest alternatives, and answer any questions.
API Design Choices
Comparison Table
| Properties | REST | RPC | GraphQL |
|---|---|---|---|
| resource-oriented | action-oriented | single endpoint | |
| data-driven | high performance | strongly-typed requests | |
| flexible | no data overfetching | ||
| self-documenting | |||
| Data | JSON | ||
| ------------- | ------------------------------- | ------------------------------------------ | -------------------------------------- |
| JSON, XML, YAML, HTML, plain text | JSON, XML, Thrift, Protobuf, FlatBuffers | ||
| Use Cases | |||
| ------------- | ------------------------------- | ------------------------------------------ | -------------------------------------- |
| web-based apps | complex microservices systems | high-performance mobile apps | |
| cloud apps | IoT applications | complex systems and microservice-based architectures | |
| client-server apps | |||
| cloud computing services | |||
| developer APIs |
Synchronous
- Client and Service interactions.
- HTTP sync between services ensures quick response times but requires both ends to be available simultaneously.
Async Messaging
- Messages are queued and processed asynchronously.
- Suitable for systems that handle varying loads.
Publish-Subscribe
- Producer publishes to a topic, and subscribers consume messages.
- Useful for decoupling components, ensuring scalable and distributed processing.
Scalability
Replication
- Data Replication:
- Copying data to ensure high availability.
- Active Data: Data currently being accessed or updated.
- Mirrored Data: Backup data, identical to active data.
Partitioning
- Dividing a large database into smaller, more manageable parts.
- Horizontal Partitioning: Rows of data are spread across multiple tables.
- Vertical Partitioning: Columns of data are spread across multiple tables.
Sharding
- Splitting data across multiple machines to increase storage and performance.
- Example: A 1TB database is split into four 256GB shards.
Load Balancing
- Distributes incoming traffic across multiple servers.
- Helps in managing large scale web services efficiently.
Caching
In-memory Cache
- Faster access as data is stored in memory.
- Example: Redis, Memcached.
- Uses: Storing frequently accessed data to reduce load on databases.
Distributed Cache
- Data cached across multiple machines.
- Ensures high availability and consistency.
- Example: Amazon Elasticache, Google Cloud Memorystore.
Caching Eviction Policies
- LRU (Least Recently Used) : Removes least recently accessed items.
- LFU (Least Frequently Used) : Removes least frequently accessed items.
- FIFO (First In, First Out) : Removes oldest data first.
- Random Eviction: Randomly removes items.
Tips for Effective Caching
- Use for session storage, communication between microservices, and database query results.
Reference:
medium.com
Top 5 System Design Interview Cheat Sheets for Developers - Medium
gist.github.com
System Design Cheatsheet - Discover gists · GitHub
www.tryexponent.com
Nail the System Design Interview: Complete Guide - Exponent