Distance Metrics in Data Science: Overview and Usage
Distance Metrics in Data Science
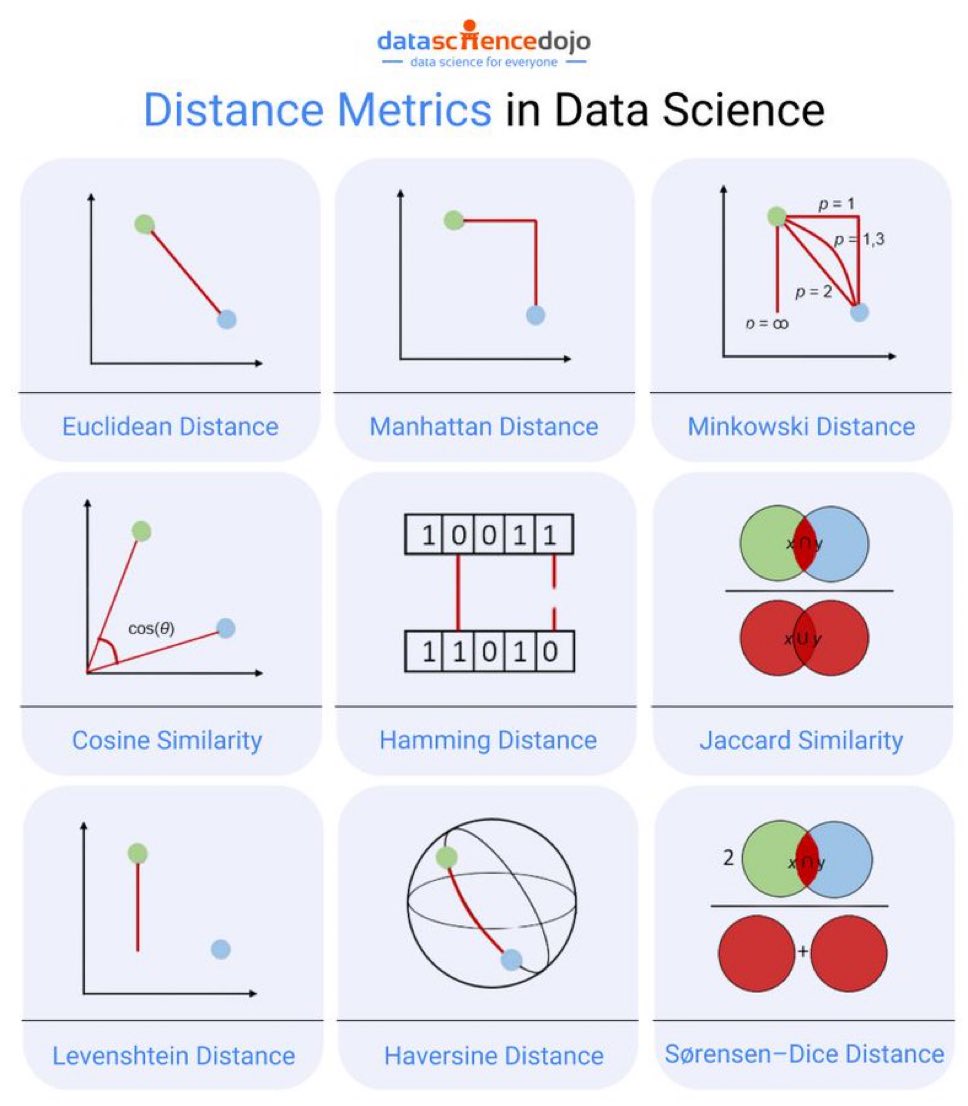
Euclidean Distance
- Description: Measures the straight-line distance between two points in Euclidean space.
- Formula:
- Usage: Commonly used in tasks requiring measurement of similarity between data points such as clustering and classification.
Manhattan Distance
- Description: Measures distance between two points along axes at right angles. Also known as L1 norm or taxicab distance.
- Formula:
- Usage: Useful in grid-based pathfinding algorithms and when differences in individual dimensions need equal treatment.
Minkowski Distance
- Description: Generalization of both Euclidean and Manhattan distance.
- Formula:
- Parameter:
- : Manhattan distance
- : Euclidean distance
- Usage: Offers flexibility with parameter, useful when specific dimensional contributions need to be balanced.
Cosine Similarity
- Description: Measures the cosine of the angle between two non-zero vectors. Values range from -1 to 1.
- Formula:
- Usage: Useful for text analysis, comparing document similarity, and situations where magnitude differs.
Hamming Distance
- Description: Counts the number of positions at which corresponding elements differ. Primarily used for binary strings.
- Formula:
- Usage: Error detection and correction in data transmission, binary string comparison.
Jaccard Similarity
- Description: Measures similarity between finite sets by comparing the ratio of intersecting elements to the union of elements.
- Formula:
- Usage: Used in clustering and information retrieval, especially in comparing sets or binary attributes.
Levenshtein Distance
- Description: Measures the minimum number of single-character edits required to change one word into another.
- Formula:
- Usage: Commonly used in text processing, spell checking, and plagiarism detection.
Haversine Distance
- Description: Measures the distance between points on the surface of a sphere. Essential for calculating great-circle distances.
- Formula: Involves spherical trigonometry.
- Usage: Ideal for geographic information systems (GIS) and applications involving global positioning.
Sørensen–Dice Distance
- Description: Measures the similarity between two samples. Similar to Jaccard Similarity but doubles the weight of intersection.
- Formula:
- Usage: Effective in ecology, biology, and other fields requiring robust similarity measurement between sets.
Reference:
medium.com
Exploring Common Distance Measures for Machine Learning and ...
www.linkedin.com
9 Distance Measures in Data Science - LinkedIn
www.analyticsvidhya.com
Understanding Distance Metrics Used in Machine Learning