DiSTRo: Efficient Distributed Training Over the Internet
Notes on DiSTrO (Distributed Training Over-the-Internet)
Overview
DiSTrO is a methodology aimed at optimizing distributed training processes, specifically focusing on bandwidth efficiency and independent node operations.
Key Points
-
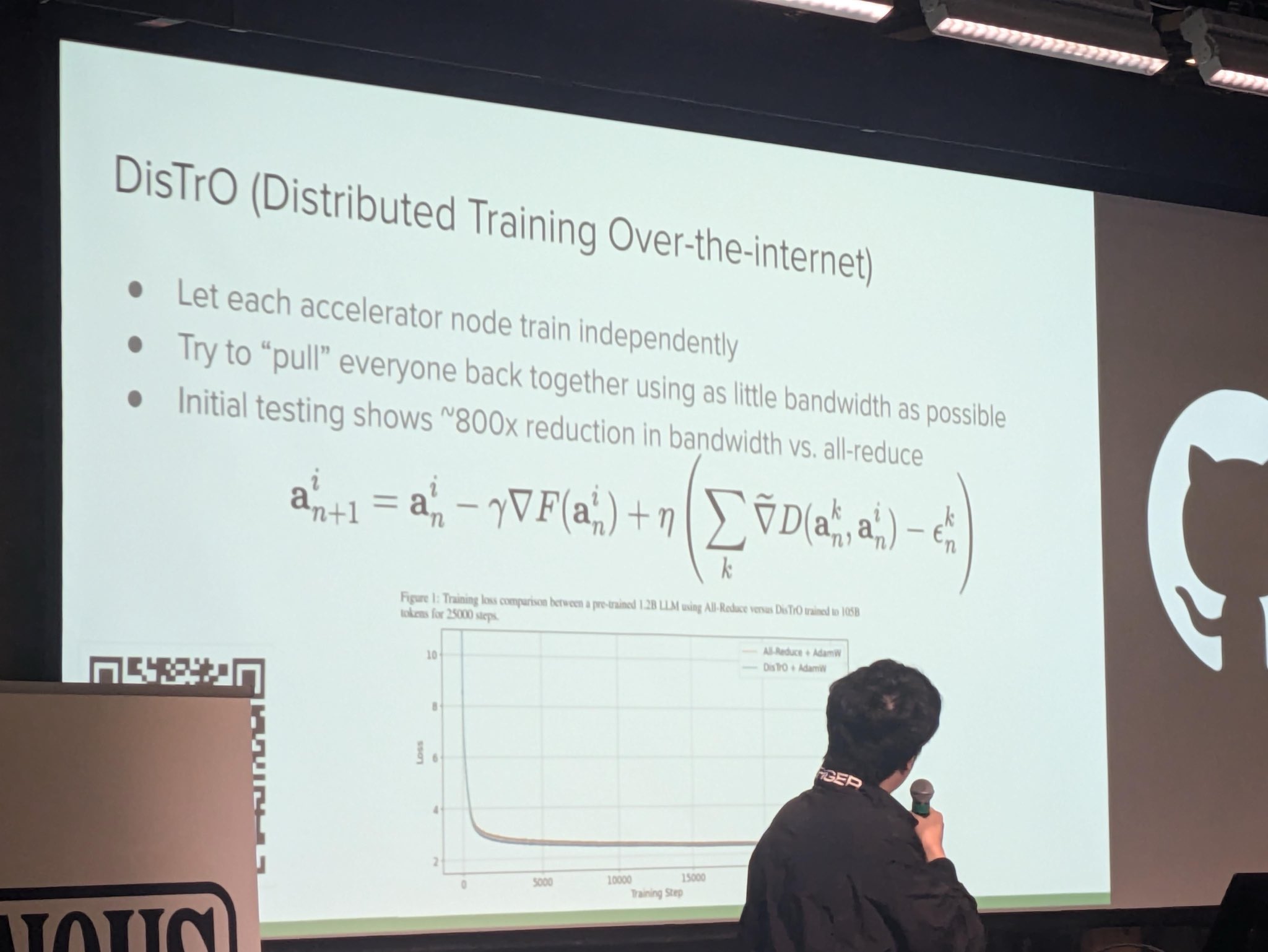
Independent Node Training
Each accelerator node trains independently. This allows for parallelism and reduces dependencies across nodes, potentially speeding up the training process. -
Efficient Bandwidth Usage
The approach tries to "pull" all nodes back together using minimal bandwidth. Efficient bandwidth usage is crucial in distributed systems to prevent bottlenecks, especially over the internet, which can be less predictable compared to local networks. -
Bandwidth Reduction
Initial testing has shown approximately an 800x reduction in bandwidth compared to traditional all-reduce methods. All-reduce is a commonly used operation in distributed training for synchronizing models, but it can be bandwidth-intensive.
Mathematical Model
The update rule for DiSTrO is expressed as:
- : Model parameters for node at step .
- : Learning rate.
- : Loss function.
- : Additional parameter influencing convergence.
- : Divergence operation to measure difference and guide updates.
- : Error term to manage discrepancies.
Insights
-
Learning Rates & Convergence
The presence of both and suggests careful tuning to balance individual training steps with overall synchronization. This balance is crucial for achieving both speed and accuracy in training. -
Error Management
Inclusion of an error term helps manage any discrepancies arising during distributed updates, potentially improving model robustness.
Visual Data
Chart Describing Training Loss
- X-axis: Training steps (ranging from 0 to 15000).
- Y-axis: Loss value (ranging from 0 to 10).
- Comparison:
- The chart compares the training loss of a pre-trained 1.28B language model using "All-Reduce with AdamW" versus "DiSTrO with AdamW".
- Observations indicate convergence patterns of the two approaches over 25000 tokens for 25000 steps.
Additional Information
-
All-Reduce
A collective operation used in distributed computing to sum values across all processes and distribute the result back to all processes. It's often used for gradient averaging in distributed training. -
AdamW
An optimization algorithm commonly used in training deep learning models, which modifies the weight decay to improve learning efficiency.
Considerations
Future exploration might include assessing DiSTrO in different network conditions or adapting it for varying model sizes and structures to understand scalability and generalization capabilities better.
Extended readings: